
Author: Jurij Mihelič, Beyond Semiconductor
In this blog post, we explore the concept of information flow tracking (IFT) from the field of computer security and its importance in enhancing data security and privacy. We begin with an explanation of what IFT is, followed by an approach to representing security policies. Next, we discuss several challenges associated with IFT, and finally, we give some potential approaches to addressing these challenges within the CROSSCON project.
What is IFT?
Information flow tracking is an area of computer security that focuses on studying methods and techniques used to monitor and control the movement of data within an information processing system as well as the movement of data across the system’s boundaries, where communication with the world external to the system takes place. It involves tracking the flow of information from the source to the destination and identifying all the intermediate steps and processes it goes through. By doing so, organizations can gain a clear understanding of how data is accessed, manipulated, and shared within their systems. And more importantly, IFT can also be used to prevent, detect, and mitigate potential security risks.
Various issues important from the security perspective may be identified using IFT, such as:
- Data exfiltration which occurs when sensitive information is moved out of the system but such an action is unauthorized. Prominent examples of this are well-known data leaks.
- Data infiltration which occurs when undesired information is moved into the system but such an action is unauthorized. Examples of this are various spoofing attacks and computer virus infections.
In particular, limiting the information flow can be efficiently utilized to ensure desired security properties such as confidentiality which is related to the assurance that data is only given to those we trust, and integrity which is related to the assurance that the data is only influenced by those we trust. In other words, the former is about monitoring and controlling operations of reading and accessing the data while the latter is about writing and modifying it.
Security policies
To use the IFT approach, the data is usually partitioned into several classes. A well-known example from the practice is a spectrum of classes from unclassified through confidential and secret to top secret classifications, which represent the MILS (multiple independent levels of security) approach. These classes are often identified via labels or tags. Obviously, the policy should allow the data to flow from the confidential class to the secret class but not vice versa. The latter restriction is often referred to as non-interference.
One way to specify a security policy is via mathematical notions of binary relations, reflexivity, transitivity, lattices, least upper bounds, etc. These have often been used in the past, but an even more simple way to specify the data-flow policy is to use a notion of a graph from the graph theory.
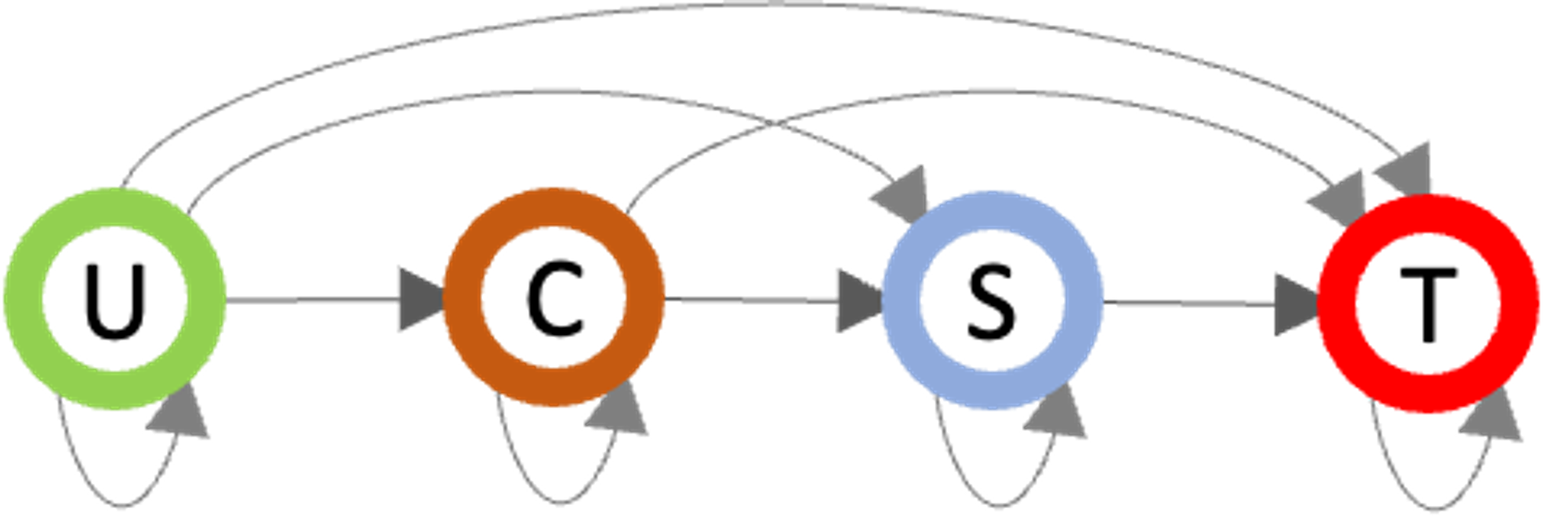
An example of the security policy modelling confidentiality of data with the four above-mentioned MILS classes is represented as a graph in the figure below. Here, the circle nodes represent the data classes while arrows represent the allowed information flow from the source to the target node.
Research challenges
There are many research challenges related to IFT such as the effectiveness of a policy as well as its efficient enforcement. As an example, consider the following policy representing the functionality of a simple firewall. Here, the tag A represents confidential data and B represents the outbox data released to the public. Furthermore, an intermediate node, denoted with F, takes care of filtering while data moves from A to B.

An important observation here is that this policy is non-transitive in the sense that the data cannot go directly from A to B, but it can go through F. The code running in F must be of high integrity, be trusted and reliable, which may be established by an independent code verification, but the security policy allows us to directly express the fact that the data is processed by such a trusted code. Nevertheless, with a transitive security policy, we are unable to express this guarantee.
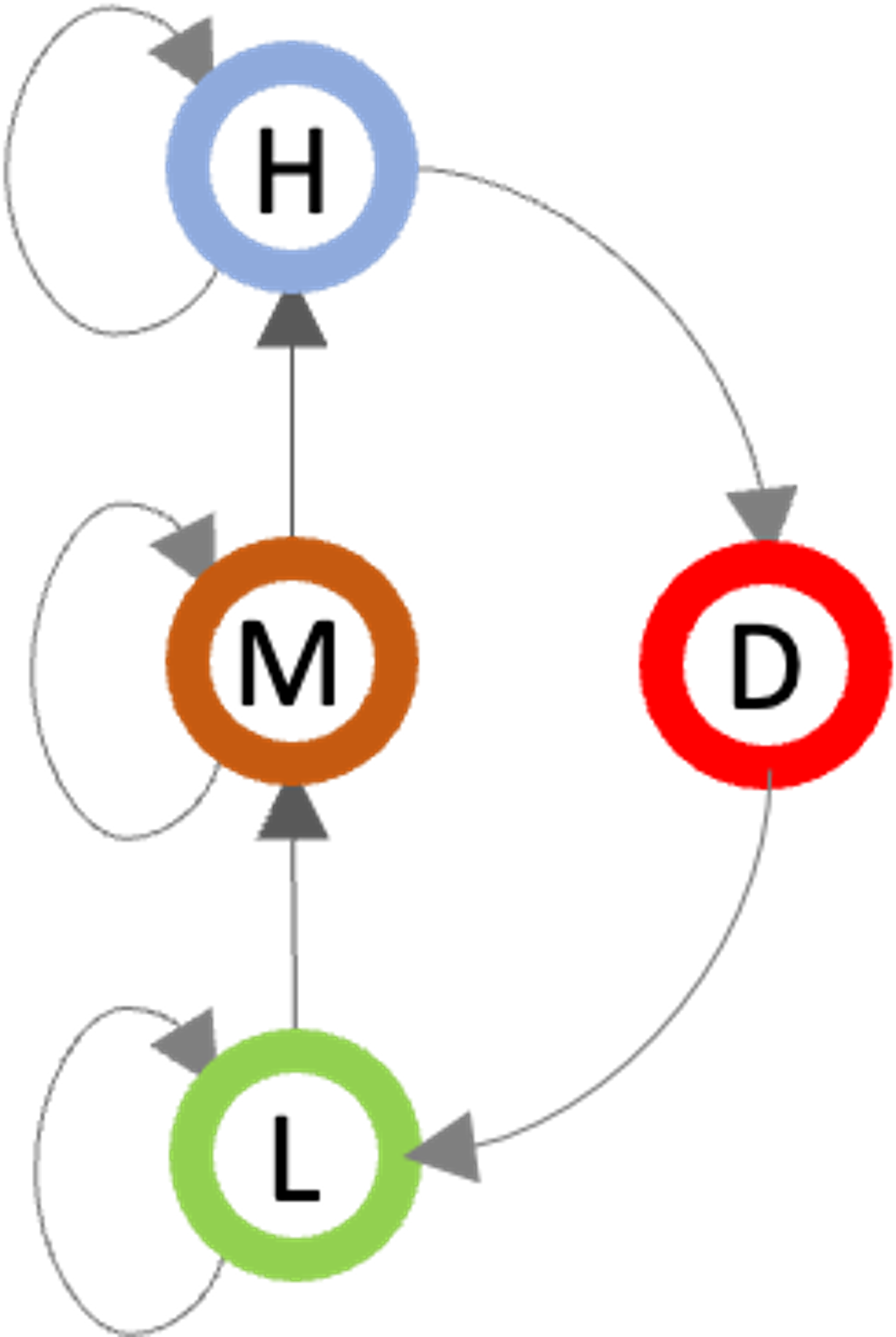
Another well-known issue is the label-creep phenomenon, which occurs when various classes of data are interacting with each other. Consequently, they move to classes with “higher” labels. One solution to this is to use so-called downgrading nodes which control the movement of data from “high” to “low” nodes. For example, consider the following policy with tags L (low), M (middle), and H (high) representing usual information processing and D representing a trusted code implementing downgrade operation.
Dynamic IFT and data-driven secure computing
An approach explored within the CROSSCON project is to exploit dynamic (performed during the information processing) IFT. We also strive to combine dynamic IFT with static program code analysis to ensure the desired security properties of the system.
We intend to use non-transitive policies and downgrading nodes to make the approach practical. We opt for a hardware-supported solution by augmenting processors with tag propagation units and perimeter guards to make the approach more efficient.
Moreover, we also propose two kinds of data-flow tracking:
- The security-oblivious one which can be used to track information flow caused by execution of ordinary machine code while being unaware of the fact that it is being dynamically verified and that the tag propagation process is also in place.
The security-aware one where an existing ISA (instruction set architectures) is augmented with special instructions that are able to move the data between designated tags. Such instructions enable us to efficiently implement inter-domain communication and downgrader widgets.
Conclusion
To conclude the blog post, let us mention that IFT is now a totally new approach but with the growing importance of safety and security it has recently re-emerged as an perspective research area.